AI Benchmarks Explained: Why Leni’s Latest Results Matter for CRE
AI Benchmarks Explained: Why Leni’s Latest Results Matter for CRE
Almost every real estate team is experimenting with AI right now, there’s no denying that. But whether the tools they’re using can be trusted with the work that actually matters is another question.
Any AI tool applied to real estate needs to accurately read source documents, reason across spreadsheets, check assumptions, push back when a prompt is flawed, and produce outputs a real investment or asset management team can review with confidence.
That’s why AI benchmarks matter. They show whether an AI system can perform well on independent tests that mirror the real demands of knowledge work. Leni recently posted top-tier results across four independent benchmarks: first on DRACO, top two on SpreadsheetBench Verified, ahead of all public models on BullshitBench, and ahead of Genspark, Manus, and OpenAI Deep Research on GAIA.
So what do those AI benchmark results actually mean?
Let’s break it down.
What Are AI Benchmarks?
AI benchmarks are structured tests used to measure how well an AI system performs a specific task.
Some AI benchmark tests measure reasoning. Others measure coding, research, spreadsheet accuracy, factuality, math, image generation, or multi-step task completion. A GPU AI benchmark, for example, typically measures hardware performance for AI workloads.
For anyone applying AI to business (like CRE teams), a relevant AI benchmark asks questions like:
Can the system produce research that holds up under review?
Can it handle spreadsheet tasks correctly?
Can it recognize when a question includes a false premise?
Can it complete a multi-step workflow without making an early mistake that derails the final output?
Why AI Benchmarks Matter in Commercial Real Estate
Commercial real estate data can get messy quickly. Important information lives across PDFs, spreadsheets, property management systems, operating statements, rent rolls, leases, market reports, investment memos, email threads, and shared drives.
So even when the data you need exists, it’s rarely available in the exact format you need.
That creates a real challenge for AI.
It’s one thing for AI to summarize a paragraph. It is another thing for AI to read a rent roll, compare it against historical operating data, identify unusual assumptions, pull market context, and turn the result into an output an analyst, asset manager, or investment committee can trust and actually use.
The margin for error is also much smaller in CRE than in many casual AI use cases. A missed lease clause, wrong NOI figure, flawed comp, incorrect rent growth assumption, or misleading market summary can affect underwriting, investor communications, and portfolio decisions.
This is the gap a lot of businesses are encountering with AI adoption:
An October 2025 EY survey showed that 99% of companies reported financial losses tied to AI-related risks, with an average loss of $4.4M per company.
JLL’s 2025 Global Real Estate Technology Survey similarly found that 92% of CRE firms have piloted AI but only 5% say they’ve achieved all of their AI goals.
That doesn’t mean AI is failing. It just means the next phase of AI adoption is about trust, accuracy, workflow fit, and execution.
Leni’s AI Benchmark Results at a Glance
Here’s how Leni performed across four major AI benchmarks:
Benchmark
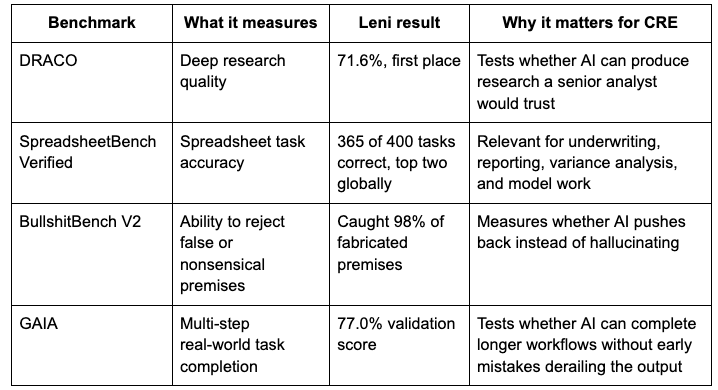
Leni placed first on DRACO, ranked in the top two globally on SpreadsheetBench Verified, outperformed all 142 public models on BullshitBench V2, and scored 77% on GAIA’s validation set.
A Closer Look at AI Benchmarks
Not all AI benchmarks measure the same skill. That’s why it is worth looking at each benchmark separately.
A system that performs well on research may not perform well on spreadsheets. A system that can answer normal questions may still fail when the prompt includes a false assumption. A system that handles one-step questions may struggle when the workflow requires multiple dependent steps.
DRACO benchmark
Developed by Perplexity AI and Harvard, DRACO measures whether AI can produce in-depth research that a senior analyst would be willing to sign off on.
That’s especially relevant for commercial real estate because research isn’t just information gathering. Good research requires judgment. It requires knowing which sources matter, which details are irrelevant, what context changes the conclusion, and how to turn scattered information into a useful recommendation.
For CRE teams, this maps to workflows like:
Market research for a new acquisition
Submarket summaries
Tenant or employer concentration research
Supply pipeline analysis
Investment thesis support
SpreadsheetBench Verified
SpreadsheetBench Verified evaluates how well AI performs on real spreadsheet tasks. This might not be a particularly flashy benchmark, but for CRE teams, it might be one of the most important.
Spreadsheets remain the operating system of commercial real estate analysis. Even teams with sophisticated systems still use spreadsheets for underwriting, budget comparisons, variance analysis, rent roll cleanup, sensitivity tables, investor reporting, and portfolio reviews.
Spreadsheet work is unforgiving. A formula error, misplaced assumption, incorrect cell reference, or broken calculation can change the conclusion.
That’s why SpreadsheetBench matters. It measures whether AI can perform the kind of structured, detail-oriented work analysts rely on every day.
For CRE teams, this connects directly to workflows like:
Comparing budgeted vs. actual NOI
Building first-pass underwriting models
Cleaning rent rolls
Creating sensitivity tables
Preparing investor reporting packages
Running variance analysis across a portfolio
BullshitBench
BullshitBench tests whether AI can push back on nonsensical questions instead of inventing an answer.
This benchmark gets at one of the most important parts of AI reliability: restraint.
One of the biggest risks with AI is not that it says, “I don’t know” but that it confidently answers a question that should have been challenged.
In real estate, flawed premises happen all the time:
“Why did occupancy drop?” when occupancy actually increased
“Summarize the lease clause that allows early termination” when no such clause exists
“Explain why this market is underperforming” when the data shows it is outperforming
“Calculate the rent growth decline” when rent growth is positive
A reliable AI system should not politely go along with the wrong assumption. It needs to flag the issue, explain what the data actually shows, and help the team correct course.
That’s also where AI hallucinations become especially dangerous. In a casual setting, a hallucination may be annoying. In investment or asset management work, it can be costly.
GAIA
GAIA measures whether AI can complete real-world tasks that involve multiple steps. It was developed by Meta and HuggingFace and tests whether AI can complete tasks without making early mistakes that throw off the final answer.
This is important because most business workflows aren’t single-prompt tasks.
A real CRE workflow may require reading documents, extracting data, checking assumptions, running calculations, comparing outputs, creating a memo, and formatting a final deliverable. If the AI makes a mistake in step two, the output in step seven may look polished but be completely wrong.
For CRE teams, this matters for workflows like:
Turning an OM, T12, and rent roll into an underwriting package
Creating a market research memo with cited sources
Building an investor update from multiple portfolio files
Producing a weekly asset management report from live operating data
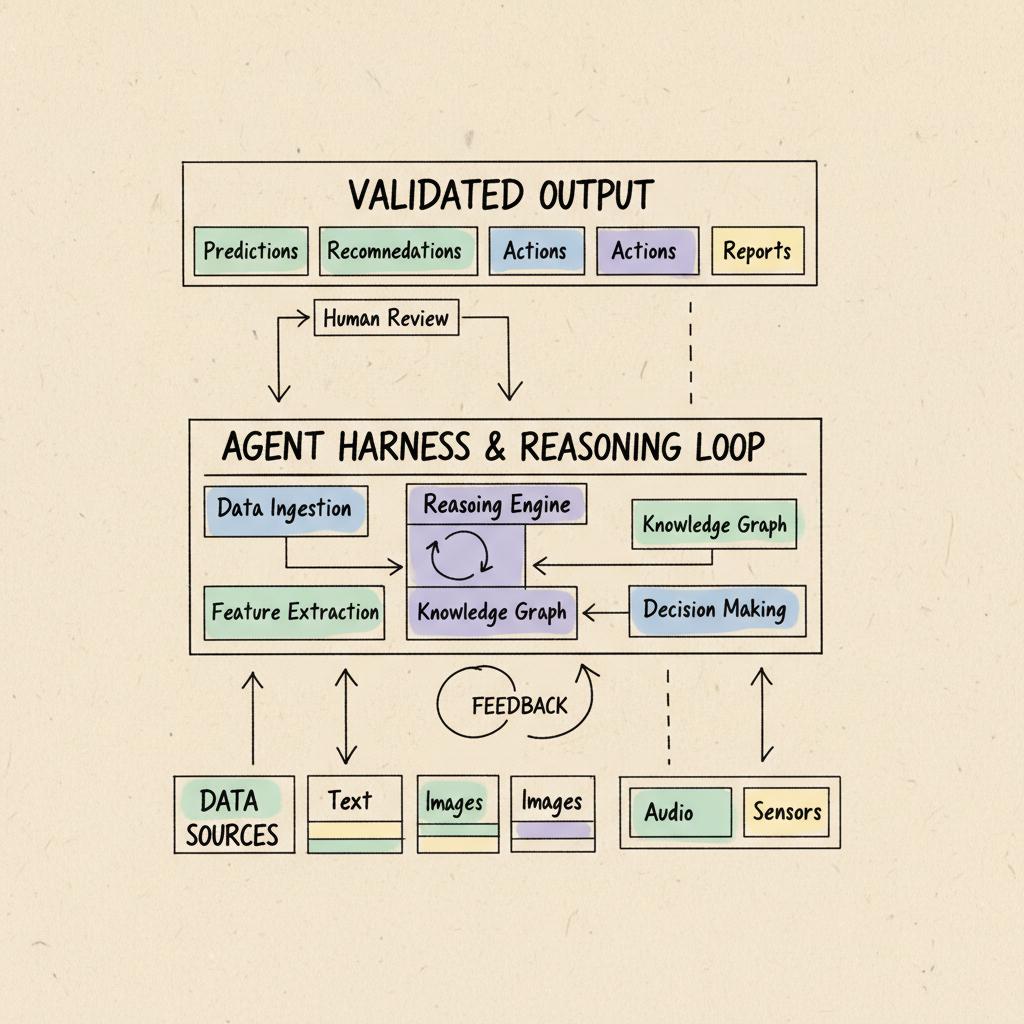
The Bigger Point: Architecture Matters As Much As The Model
AI performance benchmark results are useful, but they also point to a bigger idea: reliable AI is not only about the underlying model.
As Leni CEO and Co-Founder Arunabh Dastidar put it, “Most teams obsess over models, but the key engineering needed for effective AI adoption, which delivers highly accurate and reliable results for teams, relies on architecture or harness.”
A standalone model can generate an answer and a prompt interface can help a user ask better questions. But serious business workflows require more structure than that.
An effective workflow has to:
Understand the task
Gather the right inputs
Reason through the steps
Validate the output
Preserve context
Produce something usable in the format the team actually needs
For commercial real estate, that means AI needs to work across source materials and systems.
Leni’s agentic AI platform, for example, is designed for investment, asset management, and operations teams across CRE, pulling data from PDFs, spreadsheets, and core systems to execute complex workflows end to end. Leni’s Universal Data Model creates a standardized data framework for multifamily real estate, giving the sector a common language across proprietary formats and data silos.
That type of architecture matters because CRE data is rarely clean or conveniently packaged. A system that performs well in this environment needs the infrastructure to connect data, preserve context, validate outputs, and support workflows from start to finish.
Trust also depends on verifiability. Numbers should trace back to source data. Assumptions should be visible. Gaps should be flagged. A good answer shouldn’t force the team to redo the work just to feel confident using it.
That’s the difference between AI that looks impressive on paper and AI that can become part of an investment or asset management team’s operating rhythm.
What This Means for Real Estate Teams Evaluating AI
Benchmark results shouldn’t be treated as the only evaluation criteria. They’re signals, not the whole story.
Here’s what CRE teams should look for:
Look for Benchmark Relevance, Not Just Benchmark Bragging Rights
A high score only matters if the benchmark resembles the work your team needs done. For CRE, the most relevant benchmarks are tied to research, spreadsheets, multi-step workflows, AI accuracy, and resistance to AI hallucinations.
Ask How the AI Handles Bad Inputs
Every real workflow includes missing information, inconsistent files, unclear instructions, or flawed assumptions. A reliable AI system should ask clarifying questions, flag missing documents, identify conflicting data, and push back when the prompt includes a false premise.
Evaluate Outputs the Way Your IC or Asset Management Team Would
Can the system show its work? Can your team trace the numbers? Are assumptions visible? Are sources clear? Could the output support a decision, or is it only a nice first draft?
Pilot With Real Workflows
Don’t only evaluate AI on sanitized demos. Use your own messy files, real reports, actual rent rolls, live operating data, and common workflows.
The complexity of real-world data reveals whether a platform can handle your team’s actual environment, not just a polished sample scenario.

Why Leni’s AI Benchmark Results Matter
AI benchmarks don’t answer every question. They don’t replace customer outcomes, security reviews, workflow design, integrations, or human judgment.
But they are useful signals. They show whether an AI system can perform against independent tests that resemble the real demands of knowledge work: research, spreadsheets, factual discipline, and multi-step execution.
For commercial real estate, that is the work.
Investment and asset management teams need AI that can move from raw materials to usable outputs with accuracy, context, and restraint. As Scott Jones, Vice President of IT at Ram Realty Advisors, put it, Leni’s impact has been “faster and easier,” especially for asset management teams that are no longer stuck doing manual work.
That is the real story behind the benchmark results: not AI for the sake of AI, but a clearer signal that AI can be built for the accuracy, reliability, and workflow depth that serious real estate work requires.
FAQ
What are AI benchmarks?
AI benchmarks are standardized tests that measure how well an AI system performs specific tasks, such as research, spreadsheet analysis, reasoning, factual accuracy, or multi-step workflow completion.
Why do AI benchmarks matter?
AI benchmarks help users compare AI systems on more than marketing claims. The best benchmarks show whether AI can produce accurate, reliable, and useful outputs in task areas that resemble real work.
What AI benchmarks did Leni top?
Leni placed first on DRACO, ranked in the top two globally on SpreadsheetBench Verified, outperformed every public model on BullshitBench V2, and scored ahead of Genspark, Manus, and OpenAI Deep Research on GAIA.
Why are AI benchmarks important for commercial real estate?
Commercial real estate teams use AI for high-stakes workflows involving documents, spreadsheets, forecasts, market research, and investment decisions. Benchmarks help show whether an AI system can handle those tasks accurately and reliably.
Do benchmark results prove an AI platform is right for every team?
No. Benchmarks are useful signals, but teams should also evaluate security, integrations, source traceability, workflow fit, and performance on their own real data.

Marcio Sahade
Industry success lead focused on value delivery and AI adoption for real estate clients.
Curious About AI?
Join the largest AI community for real estate online. Get bite-sized, real-world use case videos, plus practical tips and proven strategies from top industry experts on adopting AI effectively.
MEET LENI
AI SuperAgent Purpose Built for Investors and Operators.
Experience how professionals and teams in your domain are getting the edge using AI.